This started as a cost problem, but the more interesting part was a role problem.
I had been coding with Claude all day, every day, for about four months. Claude planned, typed, fixed, reran, judged, and sometimes typed the same boring boilerplate I had asked for many times before. The work was better than what I could do alone, but the rate limits arrived earlier in the day and the bill on heavy weeks was no longer invisible.
The annoying part was not paying for good reasoning. I am happy to pay for that. The annoying part was paying reasoning-model attention to rename variables, wire obvious components, run commands, and do typing work after the shape was already decided.
I am not a developer, so "just type it yourself" is not a real answer. But the pattern was visible even to me: one model was doing too many jobs.
So I tried splitting the jobs.
What I wanted to test
The hypothesis was simple: keep the expensive model on scoping, deciding, and judging, then hand bounded implementation to a faster agent under a clear contract.
In my setup, Claude Opus was the orchestrator. Orchestrator just means the model deciding what should happen: scope, files, success criteria, and whether the result is good enough. Cursor's headless agent was the builder. Headless means it runs without a chat UI: it receives instructions, edits files, and reports back.
The contract is the important part. A contract is a small task file that says what can be touched, what counts as success, and what the builder must report. Without a contract, this is just two models improvising. With a contract, the second model has a smaller job and the first model has something concrete to judge.
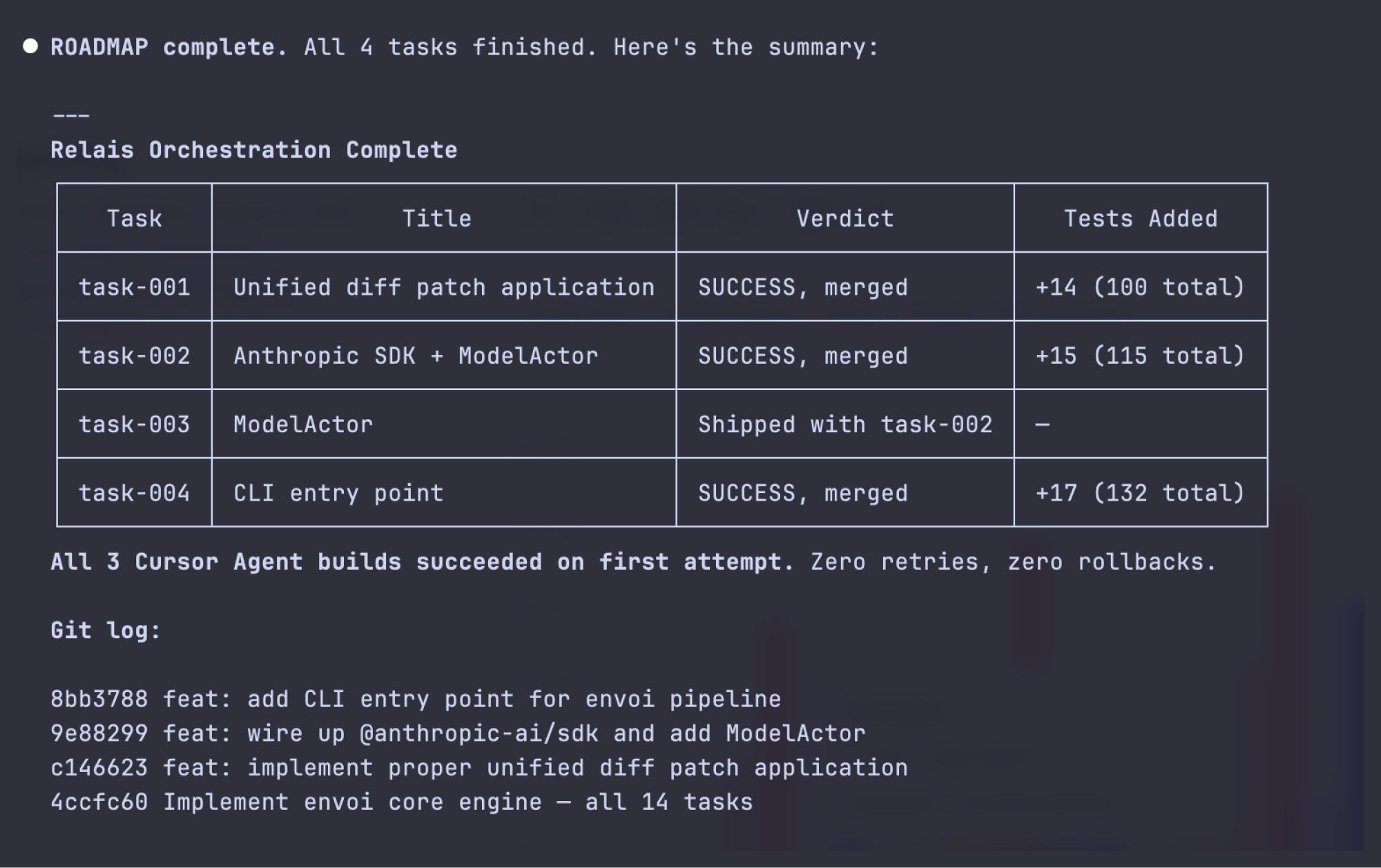
I called the experiment claude-relais. The repo is public, but I would not call it a product. It is wiring around a question: can role separation make AI coding cheaper without making it sloppier?
The dumb version worked first
The first version was two terminals.
Claude on the left wrote a plan. Cursor agent on the right read the plan and edited files. I sat in the middle, read the diff, and pasted the result back to Claude to ask whether anything looked off.
It worked on the first good task I gave it: bounded scope, named files, clear success criteria. It also failed quickly on the first bad task I gave it: fuzzy UI exploration where I had not decided what I wanted yet.
That was useful. The loop was not a replacement for thinking. It was an implementation relay after thinking had already happened.
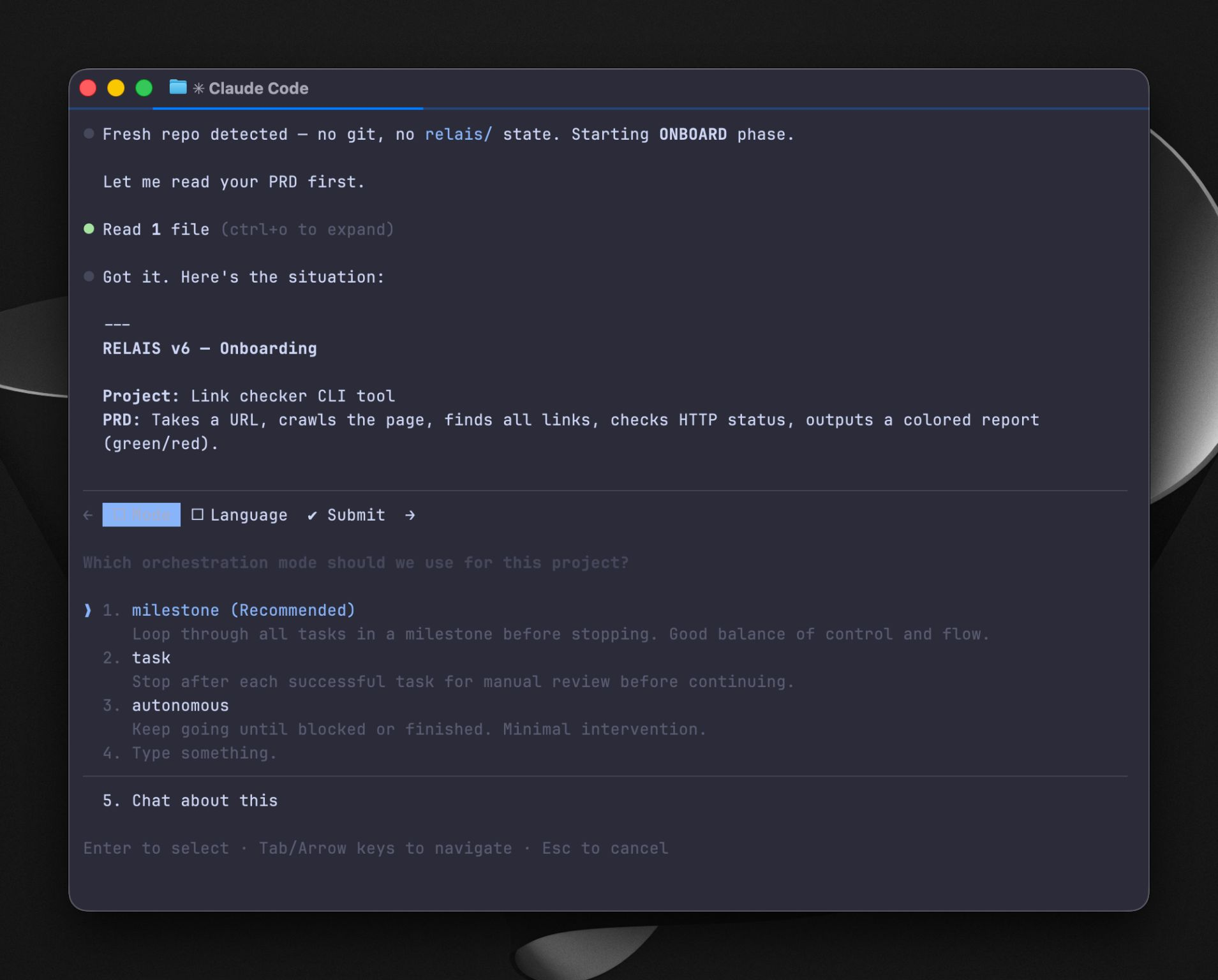
Once the manual version earned its place, I gave it files:
- Claude writes
TASK.json: scope, allowed paths, success criteria, expected report. - Cursor agent runs against
TASK.json, edits files, and writesREPORT.json. - Claude reads
REPORT.jsonandgit difftogether before accepting the result.
git diff is just the list of what changed on disk. I make Claude read the diff because the builder's report is not enough. A model can say it stayed in scope and still touch the wrong file. The diff is the evidence.
What has held up
The split works for one shape of work: clear implementation slices.
The best tasks are five to fifteen sub-steps, mostly known in advance, with files that can be named and tests or checks that can be stated. Refactors, repeated UI wiring, small feature slices, cleanup passes, and bounded bug fixes are good candidates.
I want to be precise. I have not pressed a button and watched an agent build a whole product. The pattern has been useful inside real work, but as a slice mechanism, not as magic autonomy. On rgdu.linc.fr, Opus owned strategy and slice planning while faster tooling did some of the typing once slices were clear. On this site, the same role split has helped with bounded refactors and repetitive edits. The Framer components I sell were not built with relais, but they come from the same instinct: spend expensive attention on judgment, not typing.
The cost shape is also better for me. Around 40 euros a month total in my current setup, with one Claude plan and one Cursor plan, has been enough for roughly five hours of coding a day without the same usage wall I was hitting before. That is not a benchmark. It is one person's budget, this quarter, on this stack.
What broke
The first failure mode is missing context. Anything in Claude's head that does not land in TASK.json is invisible to the builder. The builder is not being stupid when it misses it. I failed to write the contract.
The second is scope drift. Cursor sometimes wants to be helpful outside the allowed files. That sounds minor until the diff contains changes the verifier did not ask for. I spent more time than expected taming file globs and defaults so the builder stayed in its lane.
The third is overhead. For tiny one-file changes, the contract costs more than it saves. Plain Cursor inline or full Claude Code is faster.
The fourth is the important one: shaping work. The worst result came from asking the relay to handle a UI direction I had not actually decided. Claude wrote a plan based on a guess about what I wanted. Cursor executed the guess well. The result was wrong in a polished way, which is the most annoying kind of wrong.
I threw that diff away.
The lesson was blunt: relais rewards plans you trust and punishes ambiguity. If the question is still "what should this be?", do not hand it to the relay. Stay in a conversational loop until the shape is real.
How I route work now
Day to day, I think in three modes.
Cursor inline is for tight loops where I know what I want and can steer directly. Full Claude Code is for ambiguous work, architecture, hard debugging, and anything where the question itself is still changing. claude-relais sits in the middle: bounded multi-step implementation where I want one model to plan and judge, and another to type.
The rule I keep coming back to is simple: do not give the relay a plan you would not trust someone else to execute.
What I would copy first
I would not start by installing my repo.
Start with the two-terminal version. Ask one strong reasoning model to write a plan that names files, allowed changes, success criteria, and checks. Give that plan to a different builder model or coding agent. When it finishes, read the diff and ask the original model whether the diff matches its own plan.
That is enough to learn the shape. The files and automation only matter after the manual loop proves useful.
The second thing I would copy is the habit of refusing scope changes mid-build. If the builder discovers a bigger issue, it should report it, not solve it by wandering. That sounds bureaucratic until you are trying to understand why a "small" change touched eight files.
The setup gets much easier when the project already carries its own rules in AGENTS.md, CLAUDE.md, and TODO.md. That is where my local-first setup connects to this. The contract is cheap when the house rules already live next to the work.
What I would test next
I still have open questions.
I do not know where the task-size cutoff should be. Under ten minutes, I suspect the relay is usually too heavy. I have not measured it carefully enough.
I also do not know whether Cursor is the best builder. It is convenient and already indexes the repo well, but the contract sometimes fights its defaults. A more obedient headless agent might be better.
The third question is whether the verifier should be a different model from the orchestrator. Right now Claude often plans and judges. A different verifier might catch more. That is the same instinct as the double-tap, just moved later in the workflow.
The role split is the part I believe in. The current wiring is just this version of the experiment.